
Claude Opus 5凌晨曝光!最快本周平替Fable5
Claude Opus 5凌晨曝光!最快本周平替Fable5这个月刚过半,AI圈就已经卷出天际了!
来自主题: AI资讯
7459 点击 2026-07-15 11:38
 搜索
搜索
这个月刚过半,AI圈就已经卷出天际了!
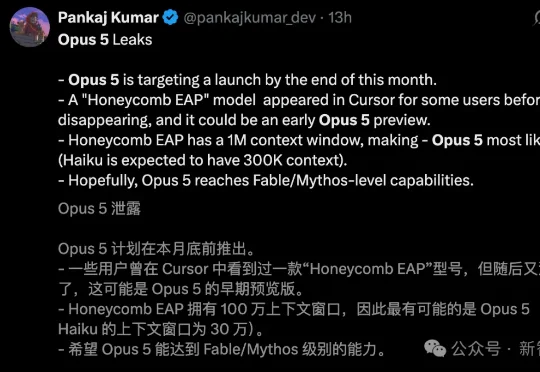
Opus 5可能要来了!有开发者意外发现,一款名为Honeycomb EAP神秘模型,1M上下文,代号「蜂巢」,在「模型列表」中短暂现身。大家一致推测,这就是Opus 5「早期预览版」,可能在月底上线。
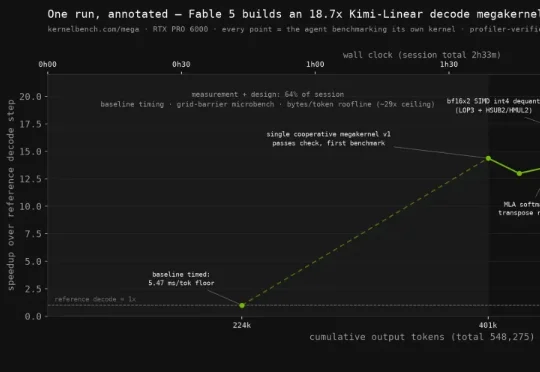
AI竟写出了,史上最快内核!在全新一轮GPU算子基准测试KernelBench-Mega中,Fable 5表现一骑绝尘。它在RTX PRO 6000,全程「纯手搓」CUDA,速度狂飙18.7倍。相比之下,强如Claude Opus 4.8也只跑出14.4倍,而GPT-5.5只有4.34倍。

Cursor AI官方发布重磅研究,实锤包括自家模型在内的顶级AI,在编程评测中大规模「偷看答案」:Opus 4.8高达87.1%的惊人成绩,断网后直接暴跌至73.0%,其中63%的「解题」竟非独立推导。

豆包大模型2.1 Pro正式发布。但字节这次没有像某些厂商那样疯狂堆参数、刷榜单,而是把刀锋对准了一个更硬核的方向:让AI真正能“干活” 。作为本次大会发布的主力模型,豆包2.1 Pro 在 Coding(编程)、Agent(智能体)、VLM(视觉语言模型)三大核心方向实现能力跃升,多项评测表现优于Claude Opus 4.6
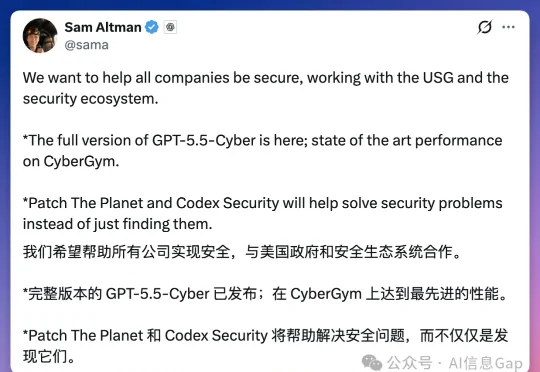
就在刚刚,OpenAI 直接放出了满血版 GPT-5.5-Cyber。CyberGym 安全评测排行榜,GPT-5.5-Cyber 得分 85.6%,单模型最高分。Claude Mythos 5 第二,83.8%。Claude Opus 4.7 排末尾,73.1%。

最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。

离谱了。 这两天,AI 圈都在疯传一个叫 Le Chaton Fat 的新模型。 30T MoE、256 个专家、100 万上下文窗口、多模态多语言,跑分全面碾压 Claude Fable 5、Claude Opus 4.8 和 GPT-5.5。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

1492 年,哥伦布驶向大西洋深处。远洋航行当然需要速度,但真正决定船队能否抵达彼岸的,是淡水、食物、船体、桅杆和帆索能否撑过漫长风暴。改写跨洋贸易的,正是这种并不浪漫的工程逻辑。 后来,荷兰人设计出